📊 Full opportunity report: VigilSAR Benchmark: There Is No Best Model on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
The VigilSAR Benchmark demonstrates that there is no one-size-fits-all AI model for defense applications. Rankings depend on specific deployment profiles, emphasizing reliability, compliance, and deployability over raw capability.
The VigilSAR Benchmark, a new public evaluation tool for defense-relevant AI models, has confirmed that there is no single ‘best’ model across all deployment scenarios. Instead, rankings are highly dependent on specific user profiles, such as cloud-based, air-gapped, or compliance-focused environments, making model selection a context-dependent decision.
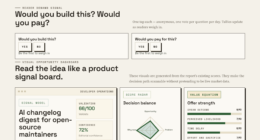
The VigilSAR Benchmark evaluates models across five axes: Capability, Reliability, Robustness, Safety & Compliance, and Efficiency & Deployability. Unlike traditional leaderboards that focus solely on raw performance, VigilSAR assesses whether models are trustworthy, compliant with regulations like the EU AI Act and GDPR, and capable of operating in restricted environments.
It introduces three buyer profiles—cloud-centric, sovereign edge, and compliance-first—and re-ranks models accordingly. The same model may top the list for one profile but fall significantly for another, emphasizing that ‘best’ depends on deployment context. The benchmark explicitly excludes harmful capabilities such as weaponization or exploit generation, focusing instead on legitimate defense-relevant knowledge work.
VigilSAR Benchmark — there is no best model
Capability leaderboards measure who’s smartest. This one scores who’s deployable — across five axes — then re-ranks by who’s actually asking.
Independent commentary, produced with AI assistance under human editorial oversight. The views are the author’s own and may change. VigilSAR Benchmark is an early-stage, in-development public benchmark; methodology, scope and results will evolve and are not a certification, authority, or guarantee of any model’s fitness, safety, or compliance. It scores defense-relevant competence and explicitly excludes weaponeering, targeting, CBRN, and exploit-generation tasks. Benchmark results are indicative, can be gamed or in error, and require independent verification; nothing here endorses any model. Model and company names are trademarks of their respective owners; mention does not imply endorsement.
Implications for Defense AI Model Selection
This development matters because it challenges the prevailing notion that a single AI model can be the best across all use cases. For defense and regulated sectors, trustworthiness, compliance, and operational constraints are often more critical than raw capability. The VigilSAR Benchmark provides a structured, context-aware approach to evaluate models, encouraging decision-makers to prioritize deployment-specific factors.
By demonstrating that rankings shift based on user profiles, the benchmark underscores the importance of tailored model selection, which could influence procurement strategies and AI deployment policies in defense and government sectors.
defense AI model deployment tools
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Limitations of Capability-Only Leaderboards
Traditional AI benchmarks and leaderboards tend to rank models solely on their performance on a set of tasks, often leading to the misconception that the top performer is universally the best. However, these rankings overlook critical deployment considerations such as compliance, robustness, safety, and operational environment constraints.
The VigilSAR Benchmark was developed to address this gap by evaluating models on multiple axes relevant to defense applications, explicitly excluding harmful or weaponizable capabilities. It is also still in early development, with methodology evolving, meaning its current rankings are indicative rather than definitive.
“No model is universally best; the right choice depends entirely on the deployment context and specific operational needs.”
— Thorsten Meyer, creator of VigilSAR Benchmark

Non-Deterministic Software Engineering: How to Build Reliable Software with AI Assistants Without Losing Quality, Security, or Control
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Uncertainties in Methodology and Future Updates
The VigilSAR Benchmark is still in early stages, and its methodology is subject to refinement. It is not yet a definitive authority, and rankings may change as the evaluation framework evolves. Additionally, it currently does not assess weaponization or exploit generation, focusing instead on legitimate defense knowledge.
It remains unclear how future updates will impact model rankings or whether additional axes, such as explainability or long-term reliability, will be incorporated.

Moving Target Defense Based on Artificial Intelligence (SpringerBriefs in Computer Science)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Next Steps for VigilSAR Benchmark Development
The VigilSAR team plans to refine its evaluation methodology, expand the set of models tested, and incorporate feedback from defense stakeholders. Future releases are expected to include more detailed profiles and possibly broader axes like explainability and long-term stability. The benchmark aims to become a more comprehensive tool for context-specific AI model selection in defense and regulated sectors.

BXQINLENX Professional 8 PCS Model Tools Kit Modeler Basic Tools Craft Set Hobby Building Tools Kit for Gundam Car Model Building Repairing and Fixing(A)
● FUNCTION—EASY TO USE—The modeler basic tools set is suitable for a beginner and advanced modeler as well.You…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Why is there no single ‘best’ AI model for defense use?
Because the suitability of an AI model depends on specific deployment requirements, such as operational environment, compliance needs, and trustworthiness, rankings vary based on these factors.
How does VigilSAR differ from traditional AI leaderboards?
VigilSAR evaluates models across multiple axes relevant to defense, including safety, compliance, and deployability, and re-ranks models based on different user profiles, unlike traditional leaderboards that focus solely on capability.
Is the VigilSAR Benchmark final and authoritative?
No, it is still in early development, with methodology evolving. Its rankings are indicative and subject to change as the framework improves.
What models are excluded from the VigilSAR Benchmark?
Models that demonstrate offensive, weaponized, or exploitative capabilities are explicitly excluded to focus on trustworthy, defense-relevant knowledge work.
How can organizations use the VigilSAR Benchmark?
Organizations can evaluate and select models based on their specific operational context, prioritizing safety, compliance, and deployability over raw performance alone.
Source: ThorstenMeyerAI.com